Is grep all you need? For agent memory, often yes.
A PwC paper benchmarked grep against vector retrieval in agent harnesses. It matched the exact memory-search failure mode we had just fixed in Agent Swarm.
Last week our memory search looked smart and acted dumb.
A worker would ask for something concrete: a PR number, a task ID, a schedule name, a config key, a date from a previous incident. The memory system returned plausible neighbors. They sounded related. They were often useless. The exact witness was somewhere in the corpus, but vector search ranked fresher noise above the old canonical fact.
Then a new paper landed with a title that felt written for our incident report: “Is Grep All You Need? How Agent Harnesses Reshape Agentic Search”, by Sahil Sen, Akhil Kasturi, Elias Lumer, Anmol Gulati, and Vamse Kumar Subbiah at PwC. The paper evaluated grep and vector retrieval on a 116-question LongMemEval-S subset across Chronos, Claude Code, Codex CLI, and Gemini CLI.
The paper did not say embeddings are dead. It said the retrieval layer, the harness, and the way results are delivered interact. For conversation memory full of exact spans, lexical search is a very hard baseline to beat.
Our bug was not bad embeddings
Agent Swarm memory search uses SQLite plus OpenAI text-embedding-3-small vectors at 512 dimensions. That sounds like the obvious place to blame when recall gets weird. It was not the root cause.
The failure was a ranking system that made sensible local choices and produced bad global behavior. Before PR #696, every memory used the same 14-day exponential recency decay:
compositeScore = cosineSimilarity * 2 ** (-ageDays / 14)That multiplier crushed old canonical memories. A curated 76-day-old memory, even if it was exactly the thing the agent needed, kept only about 2.3% of its score. A one-day-old task completion that merely sounded related could outrank it.
Two other issues compounded it. There was no minimum similarity floor, so the API tried to fill the requested limit even when only a couple of rows were truly relevant. And 1,634 rows had been embedded at 1536 dimensions by a custom provider that ignored our 512-dimension request, making those rows invisible to the 512-d search path until re-embedded.
Agent memory data
The decay bug was not semantic
A 76-day canonical memory fell to 2.3% of its score under the old flat half-life
The paper found the same shape
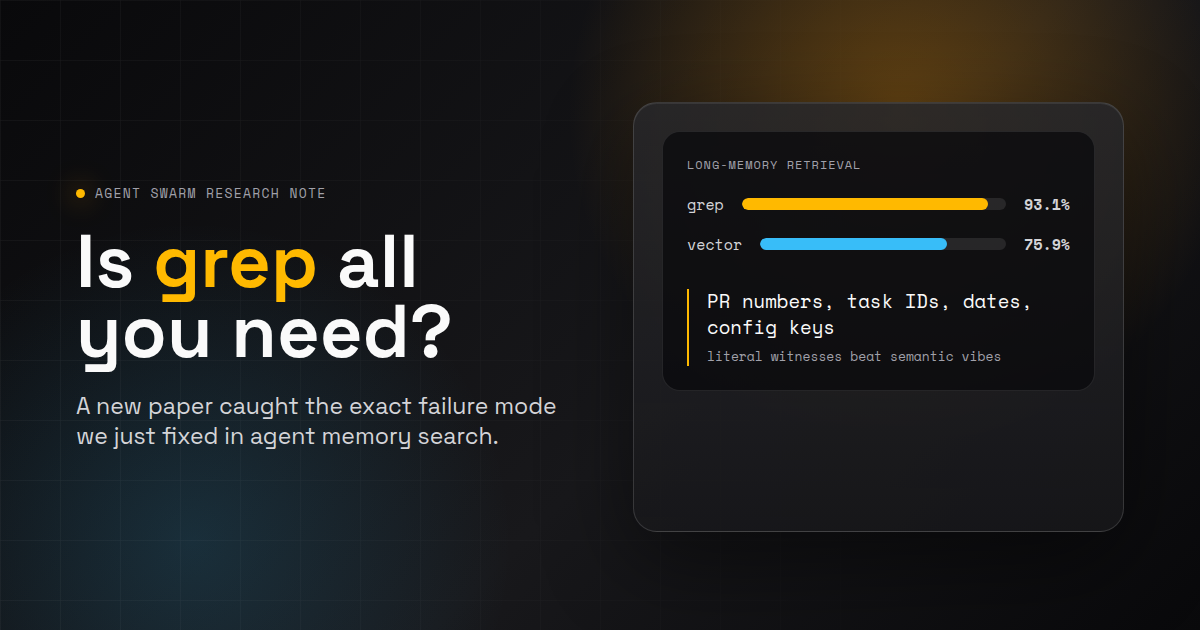
In Table 1, Sen et al. report overall accuracy on the 116-question LongMemEval-S subset. In the inline result configuration, grep beat vector retrieval for every harness-model pair they tested. Claude Opus 4.6 under Chronos reached 93.1% with grep versus 83.6% with vector retrieval. GPT-5.4 under Codex CLI also hit 93.1% with grep, while vector retrieval was 75.9%.
Agent memory data
Grep beat vector in every inline run
Table 1, arXiv 2605.15184: accuracy on 116 LongMemEval-S questions
Source: Sen et al., PwC, arXiv:2605.15184, Table 1. The paper also reports programmatic file-based tool delivery; those results are more mixed and are part of the reason the harness matters. The benchmark subset comes from LongMemEval, Wu et al.
The reason is not mysterious. LongMemEval questions often ask for literal evidence: dates, counts, preferences, exact statements, and spans scattered across long conversations. Lexical search can find the string. Vector search has to translate the query and the evidence into an embedding space, then hope the nearest neighbors preserve the exact witness.
Our corpus has the same fingerprint. Swarm memory is full of PR numbers, task identifiers, schedule IDs, environment variable names, migration filenames, model names, dates, and operational rules. When a worker asks, “what PR fixed the memory-search relevance issue?” the answer is not a theme. It is #696.
Harnesses matter almost as much as retrievers
The paper's second useful finding is that retrieval accuracy is not a property of the retriever alone. The same Claude Opus 4.6 backbone with inline grep scored 93.1% in Chronos and 76.7% in Claude Code. Same model class. Same retrieval family. Different harness.
Harness effect
Same model, different harness
Claude Opus 4.6 moved from 93.1% to 76.7% with inline grep when the harness changed
-16.4 pts from harness alone for inline grep
That matters for agent builders because the harness decides how tools are described, how results enter context, how much output is visible at once, and whether the model must take extra actions to inspect files. A retrieval benchmark that ignores the harness is measuring only part of the product.
This is also where the paper avoids the cheap take. In the programmatic file-based configuration, vector retrieval beats grep on five of ten harness-model pairs. Codex CLI with GPT-5.4 is the sharpest warning: inline grep scored 93.1%, but programmatic grep dropped to 55.2%, while programmatic vector scored 67.2%. Grep is cheap. End to end tool use is not automatically easy.
What we shipped
We had already shipped the immediate vector-search health fixes by the time we read the paper.
PR #684: keep the vector store from falling over
We capped sqlite-vec KNN requests at 4,096 and added hourly expired-row garbage collection. That fixed the hard failure mode where memory-search could exceed sqlite-vec's K limit as the table grew.
PR #696: fix noisy relevance
We made recency decay source-aware: manual memories do not decay, file-indexed memories use a 180-day half-life, task completions keep the 14-day half-life, and session summaries use 7 days. We added a 0.10 similarity floor, source quality multipliers, protected manual memories from automated deletion, validated embedding dimensions at write time, and added a boot-time re-embed backfill for wrong-dimension rows.
That made vector memory search less noisy. It did not turn it into grep. The paper clarified the next step: for this kind of corpus, lexical retrieval should not be a desperate fallback a worker reaches for after semantic search fails. It should be part of the retrieval path.
The practical rule
If your agent memory contains literal witnesses, start with lexical. That includes:
- PR numbers, issue IDs, task IDs, customer-safe record keys
- dates, times, schedules, release names, migration filenames
- environment variables, config keys, API routes, CLI flags
- quoted user preferences, exact decisions, and incident labels
Use semantic search where it is actually semantic: fuzzy discovery, paraphrase, concept matching, and cases where the query and the answer do not share surface words. Then fuse the two paths instead of asking one ranking signal to do every job.
Our next memory-search architecture should be hybrid: SQLite FTS5 for exact witnesses, vectors for semantic recall, and reciprocal rank fusion so the caller sees one list without pretending the scores mean the same thing.
The lesson is less glamorous than “replace RAG with grep.” It is also more useful. Agent memory is not one data type. Some memories are durable facts. Some are stale logs. Some are procedures. Some are exact strings the next worker needs to recover under pressure. The retrieval system has to know the difference.
Sen et al. gave us benchmark evidence for something production had already taught us the hard way: when the question is literal, a nearest neighbor can be farther away than a string match.
/ references
Sources and further reading
FAQ
Does this mean vector search is bad for agent memory?
No. The practical lesson is narrower: when the corpus is full of literal witnesses like dates, IDs, PR numbers, config keys, and exact user statements, lexical retrieval should be a first-class path. Semantic search still helps with paraphrase, concept recall, and discovery queries.
What did Agent Swarm change after the memory-search incident?
PR #696 added source-aware recency decay, a minimum similarity floor, source quality multipliers, protected manual memories, embedding dimension validation, and a boot-time re-embed backfill. PR #684 had already capped sqlite-vec KNN queries and purged expired memory rows.
Has Agent Swarm replaced memory-search with grep?
Not yet. The shipped fix made vector memory-search much less noisy. The next architectural step suggested by the paper is hybrid retrieval: SQLite FTS or another lexical layer fused with vector search, likely via reciprocal rank fusion.
Related field notes
Memory Poisoning: Why Persistent Agent Memory Is a Time Bomb
Persistent memory without decay, provenance, and quarantine is not a learning system. It is shared mutable global state dressed in vector embeddings.
The Success Penalty: How Our Agent Swarm Got 70× Slower Over 6 Months
Every task your swarm completes makes the next session slightly slower to start until memory gets treated like a database instead of a log file.
Nobody Prompt-Injected Our Agents — They Escalated Their Own Privileges
How the OWASP Top 10 for Agentic Applications maps to real threats in autonomous swarms. Spoiler: the danger is inside.