The paper did not redesign the swarm. It named it.
A unified modeling framework for LLM agents validates Agent Swarm's core architecture: active and passive core-agents, five internal modules, and a security module as the next frontier.
Every so often a paper arrives that does not teach you a new trick. It gives you better names for the thing production already forced you to build.
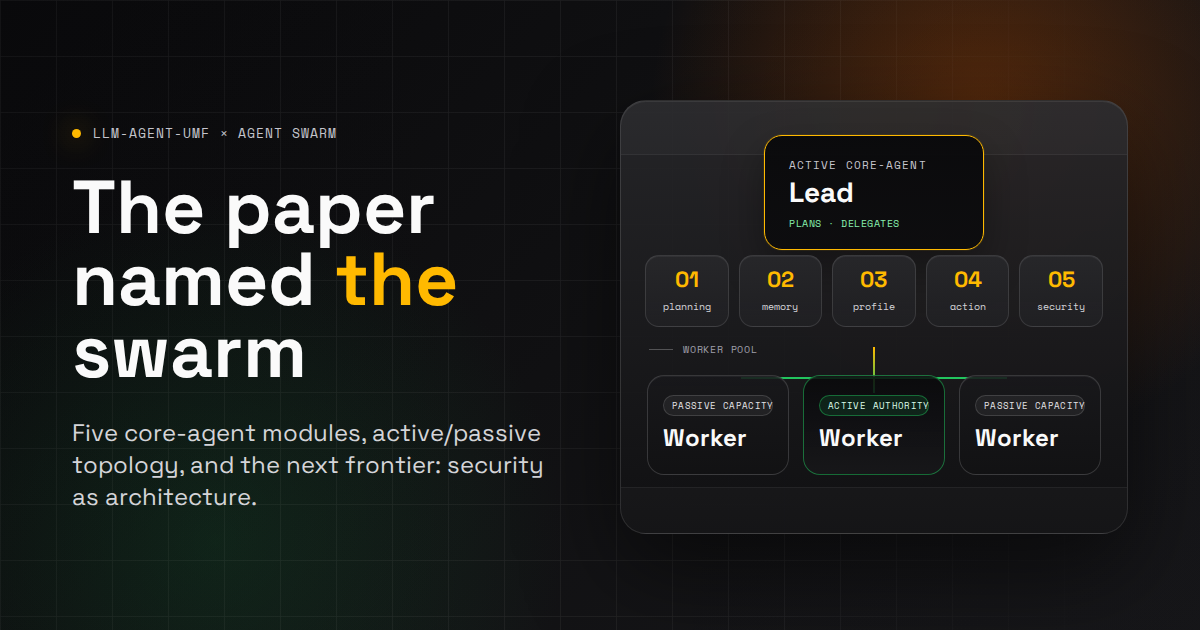
That is what happened with “LLM-Agent-UMF: LLM-based Agent Unified Modeling Framework for Seamless Design of Multi Active/Passive Core-Agent Architectures”, by Amine Ben Hassouna, Hana Chaari, and Ines Belhaj. The paper proposes a core-agent as the central coordinator inside an LLM agent, then breaks that core-agent into five modules: planning, memory, profile, action, and security.
If you run Agent Swarm, this should feel uncomfortably familiar. We have a Lead that plans and delegates. Workers with durable memory and explicit profiles. MCP tools as the action surface. Lifecycle hooks and task state as the coordination substrate. A Slack thread where humans can steer the work without opening a dashboard.
The validation is not “we should copy LLM-Agent-UMF.” It is that an independent academic framework converged on the same shape: modular core-agents, explicit profiles, active/passive coordination, and security as the missing first-class layer.
The core-agent is the missing architectural noun
The paper's useful move is separating three things that often get blurred together: the LLM, the tools, and the software entity that coordinates between them. The authors call that third entity the core-agent. It is the pivotal interface that orchestrates LLMs, tools, and the environment so high-level goals can become actions.
That distinction matters because a serious agent system is not just a model with tool calls. The model reasons. The tools act. The core-agent decides how reasoning, memory, profile, tool feedback, human feedback, and policy become one coherent run.
LLM
The reasoning engine. Powerful, swappable, and insufficient on its own.
Tools
The action boundary: GitHub, Slack, filesystem, browser, CI, search, databases, and custom MCP tools.
Core-agent
The coordinator that holds planning, memory, profile, action, and security together across a run.
This is also why the Agent Swarm product thesis is not “another wrapper around Claude Code” or “just a queue of agents.” The durable value is the operating system around model calls: memory, profiles, skills, tools, traces, task state, permissions, review loops, and the human surfaces where direction enters the system.
Active and passive is the right split
LLM-Agent-UMF classifies core-agents by authority. An active core-agent has all five modules and can manage complex tasks. A passive core-agent is non-authoritative and executes specific actions, with a smaller structure focused on action and security. The paper then proposes multi-core architectures, including a one-active-many-passive design where one manager dynamically allocates work to passive cores.
Agent Swarm is not a static diagram. Its topology changes by phase. When a request enters Slack, the Lead is the active core-agent. The worker pool is passive capacity. When tasks fan out, each claimed worker becomes an active core-agent for its own run: it plans locally, retrieves memory, applies its profile, uses tools, and reports back. At review time, authority collapses back toward the Lead, CI, GitHub, and the human reviewer.
Active / passive topology
The swarm changes shape by phase
Active authority concentrates in the Lead during intake and review. During execution, authority spreads across workers that become active core-agents for their own runs.
Source for the active/passive distinction: LLM-Agent-UMF, Sections 3.4, 4.1, and 4.4. The Agent Swarm phase model is our mapping onto the shipped Lead/worker task lifecycle.
This is a better mental model than arguing whether a swarm is “one agent” or “many agents.” A production swarm is a system of core-agents with changing authority. The Lead owns global coordination. Workers own local execution. Humans and automated checks own the final boundaries.
The five modules map almost too cleanly
The paper defines five modules inside the core-agent. The mapping to Agent Swarm is direct enough that it is worth spelling out.
Planning
Decompose tasks, generate plans, evaluate alternatives, and incorporate feedback from humans, tools, and sibling core-agents.
Lead decomposition, task dependencies, workflow DAGs, per-worker plans, tool feedback, CI feedback, and Slack review loops.
Validated. Planning is not a prompt trick; it is a runtime responsibility.
Memory
Store and retrieve information needed for decisions and execution; unlike static knowledge, it supports read and write operations.
SQLite + embeddings, memory-search, completed task outputs, indexed files, skills, session summaries, and markdown memories.
Validated. The swarm gets sharper because memory persists outside the model.
Profile
Describe identity, role, constraints, persona, preferences, and task-specific behavior for the core-agent.
SOUL.md, IDENTITY.md, CLAUDE.md, TOOLS.md, AGENTS.md, installed skills, repo guidelines, and standing orders.
Strongest validation. We literally ship profile files as first-class runtime inputs.
Action
Bridge the LLM to external systems through tools, APIs, human-machine interaction, and execution surfaces.
MCP tools, shell, GitHub/GitLab CLIs, Slack, Linear, browser QA, filesystem, scripts, workflows, and connectors.
Validated. Action is mediated through explicit tool boundaries rather than hidden magic.
Security
Layer safeguards for ethical use, privacy, robustness, prompt/response checks, and trust boundaries.
Merge tiers, no force-push rules, repo guidelines, scoped credentials, task permissions, public-PR scrub rules, and CI gates.
The gap. We have governance, but not yet a discrete enforced security module.
Profile is the underrated validation
The paper's Table 3 projects state-of-the-art agents onto the five-module model. The table is useful because it shows how uneven the architecture is in the literature. Action is everywhere. Planning and memory are common. Security appears in only a handful of rows. Profile is present in some sophisticated systems, but absent or under-specified in many.
That is where Agent Swarm looks less like a wrapper and more like an AI-native operating system. Each worker has durable identity files. The Lead has standing orders. Repos carry local instructions. Skills are procedures the agent can invoke. The profile is not a paragraph at the top of a prompt; it is a maintained module with files, hooks, memories, and task-specific overlays.
SOUL.md -> persistent motivation, boundaries, operating style
IDENTITY.md -> name, role, expertise, track record
CLAUDE.md -> repository and runtime instructions
TOOLS.md -> environment-specific operational knowledge
AGENTS.md -> task and repo-local standing orders
skills/* -> procedural memory the agent can invoke by nameThis is one of the places where our workshop framing matters: AI-native is not “we use AI tools.” It is architecture, decision-making, user experience, and lifecycle shaped around AI from the outset. A profile module is what makes an agent feel less like a disposable chat session and more like a teammate with accumulated context.
LLM-Agent-UMF mapping
Agent Swarm covers the five-module core-agent shape
Paper coverage counts rows in Table 3 where a module is present or minimally implied. Agent Swarm is a qualitative self-assessment of the shipped architecture.
Source for the surveyed-agent comparison: LLM-Agent-UMF, Table 3. Counts treat full and minimally implied modules as present, exclude the paper's N/A hypothesis row, and include the table's split Gorilla modes as rows. Agent Swarm values are qualitative, not a benchmark.
The paper is also a warning
The easiest way to misuse this paper would be to treat it as a victory lap. The authors are explicit about the module most frameworks neglect: security. They describe safeguards for prompts, responses, data privacy, robustness, trust boundaries, and defense in depth. They also point to privacy risks when multiple core-agents and external service providers exchange data.
Agent Swarm has real guardrails today. Workers cannot merge without authority. Repo guidelines define PR checks. Public PRs have scrub rules. Credentials are scoped. CI blocks unsafe changes. Slack keeps a human-visible audit trail. The system is not lawless.
But a lot of that safety still lives as instruction, convention, and review discipline. That is not the same as a discrete security module. A prompt can be ignored. A checklist can be missed. A worker can misunderstand a boundary. If the swarm is going to become the operating layer for more of a company, security has to move from “remember the rule” to “the architecture enforces the rule.”
The next step is not more policy text. It is a security core module: explicit permission manifests, pre-action checks, data egress classification, credential scopes, route-level redaction, and audit events that reviewers and agents can both inspect.
What we build next
LLM-Agent-UMF gives us a useful roadmap because it validates the parts we already made concrete and names the part we should formalize next. In our terms, this is the Build-the-Machine-that-Builds-the-Machine layer: safe, reliable, observable, scalable, and easy enough that agents can check their own work before a human has to.
1. Make security a module, not a memory
Treat policy as code: tool permission manifests, protected routes, per-task scopes, typed data classifications, and automatic denial paths before an unsafe action reaches the model.
2. Give every module observability
Planning, memory, profile, action, and security should emit inspectable events. A reviewer should be able to see which memory mattered, which profile rule applied, which tool boundary fired, and why a guardrail allowed or blocked the next action.
3. Keep the active/passive boundary dynamic
A worker should be passive while waiting, active while executing, and constrained when it crosses a review boundary. The system should make that state visible and enforce different permissions at each phase.
4. Preserve the owned learning loop
Models will keep changing. The compounding layer should stay ours: memory, profiles, tools, traces, skills, evals, and the operational feedback loop that improves every run.
The practical lesson is the same one we took from the grep paper: good external research is most useful when it validates or sharpens a production scar. The paper does not replace our roadmap. It gives us a cleaner language for it.
Agent Swarm was already built around core-agents. Now we have the vocabulary to explain it: active and passive authority, five internal modules, and a security layer that deserves to become as real as planning, memory, profile, and action.
That is what AI-native architecture looks like in practice. Not a bigger prompt. A system whose intelligence compounds because the modules around the model are durable, inspectable, and owned.
/ references
Sources and further reading
FAQ
Is Agent Swarm an implementation of LLM-Agent-UMF?
No. Agent Swarm was not designed from the paper. The point is stronger: an independently built production swarm maps cleanly onto the paper's core-agent vocabulary, five modules, and active/passive topology.
What is the biggest validation point?
The profile module. Agent Swarm gives every agent durable profile files such as SOUL.md, IDENTITY.md, CLAUDE.md, and TOOLS.md. The LLM-Agent-UMF survey shows profile is missing or under-specified in many surveyed systems.
What is the biggest gap?
Security as a discrete enforced module. Agent Swarm already has governance rules, merge tiers, permissions, and operational constraints, but too much of that is still prompt and process rather than a separate guardrail layer with explicit policy, checks, and audit surfaces.